Azure Search for Jekyll
December 5, 2016 in Azure JekyllI added Azure Search to my static site built with Jekyll through the use of Azure Functions. Best part, it’s free*.
This example is for Jekyll, it will work with any static site. The only thing Jekyll specific is the JSON representation of the site, and any static site generator should be able to build that file. I’ve used (Pretzel and PieCrust as well, they are both nice tools, but hosting on GitHub pages has it’s advantages).
Creating a JSON of All Posts and Pages
The first thing I did was create a page in Jekyll to produce a JSON representation of all the Posts and Pages from my site. I added a new piece of meta-data to the front matter to indicate whether each page should be indexed for search. This way I can be sure that pages like my RSS feed, SiteMap and my search.json don’t get indexed.
---
layout: nil
includeInSearch: false
---
{% assign pages = site.pages | where:"includeInSearch", "true" %}
[
{% for p in site.posts %}
{
"type": "post",
"title": "{{ p.title }}",
"publishDate": {{ p.date | jsonify }},
"categories": [{% for cat in p.categories %}"{{ cat }}"{% unless forloop.last %},{% endunless %}{% endfor %}],
"tags": [{% for tag in p.tags %}"{{ tag }}"{% unless forloop.last %},{% endunless %}{% endfor %}],
"url": "{{ p.url }}",
"content":{{ p.content | strip_html | json_escape | jsonify }},
"excerpt": {{ p.excerpt | json_escape | jsonify | remove: '\n' }}
}{% unless forloop.last %},{% endunless %}
{% endfor %}
{% for p in pages %},
{
"type": "page",
"title": "{{ p.title }}",
"categories": [{% for cat in p.categories %}"{{ cat }}"{% unless forloop.last %},{% endunless %}{% endfor %}],
"tags": [{% for tag in p.tags %}"{{ tag }}"{% unless forloop.last %},{% endunless %}{% endfor %}],
"url": "{{ p.url }}",
"content":{{ p.content | strip_html | json_escape | jsonify}},
"excerpt": {{ p.excerpt | rstrip | json_escape | jsonify }},
"description": {{ p.description | json_escape | jsonify }}
}
{% endfor %}
]
That’s simple enough. I had actually created that over a year ago when I first started to think about using Azure Search. I abandoned that attempt partly because it was going to be a manual process and I was worried I might forget the step to populate the index.
You can see the resulting search.json here
Function Triggered by a GitHub Webhook
The next thing I needed to do was get that into Azure Search in some automated fasion. For this I used an Azure Function with GitHub Webhook for a trigger. I’m going to assume you’ll be able to figure out how to setup a Function App and create the GitHub Webhook function from the Templates available.
The new function should look something like this: 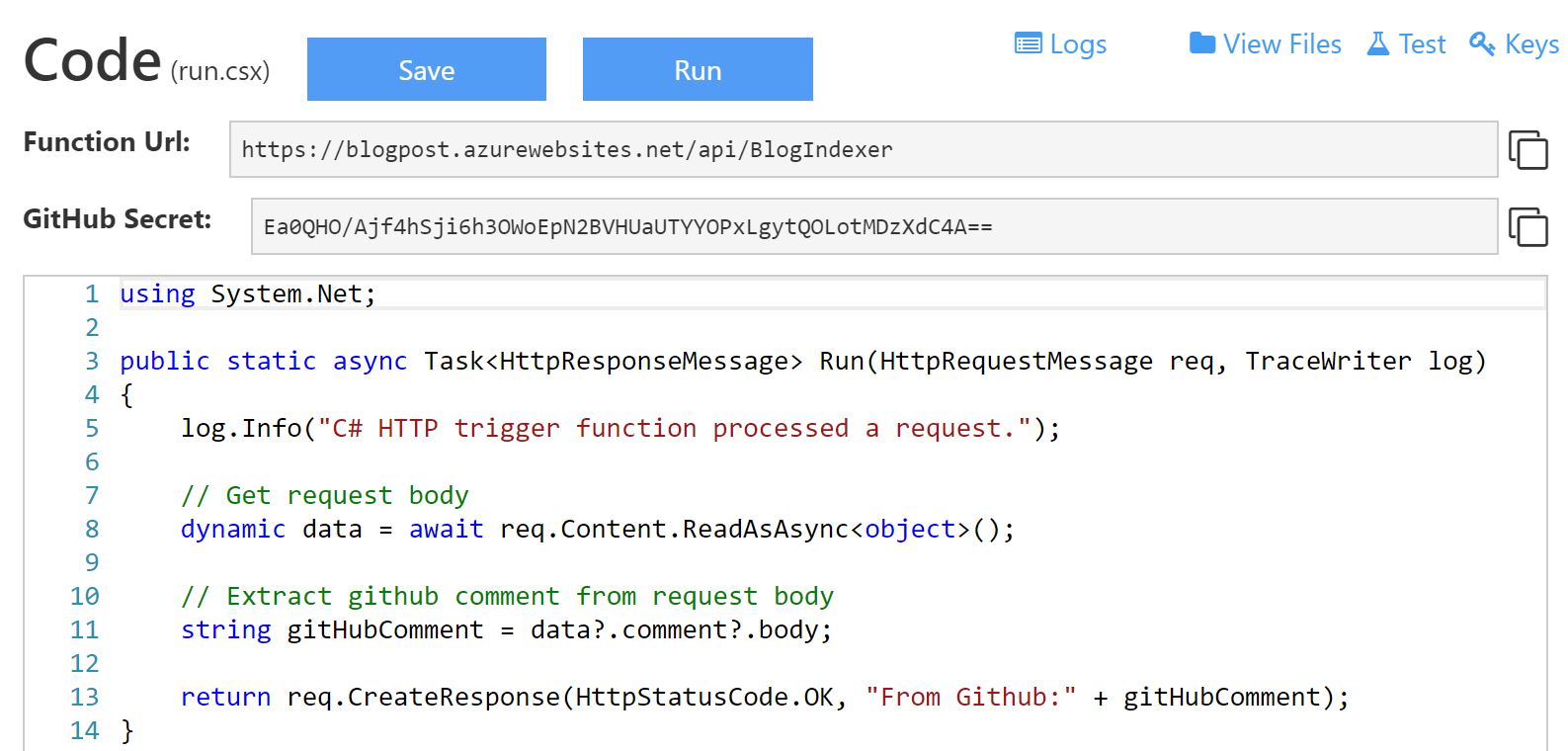
Note that the GitHub Secret that is listed is action the _master admin key, and what you really need is the default function key (more info). Also, that Function App will be gone before I post this, so don’t worry about me sharing that key :)
Setting Up the GitHub Webhook
Next step is to go over to GitHub and create the WebHook: 
Then scroll down a bit more and choose Let me select individual events That opens up of the list of events that will trigger the WebHook. Uncheck Push and check Page Build. That will trigger the WebHook to index the blog whenever the Jekyll site gets built. For debug purposes I also put a check in Watch. That way when I wanted to test everything I could just UnStar/Star my repo.
At this point we can test everything to ensure that the Webhook is working properly and our function is running. Once you confirm that is working you it’s time use the function to populate our index.
Loading the JSON into Azure Search
First thing we need to do is bring in a reference to the Azure Search SDK. To do this you need to create a project.json file in the BlogIndexer folder.
{
"frameworks": {
"net46":{
"dependencies": {
"Microsoft.Azure.Search": "1.1.3"
}
}
}
}
After that it’s just a matter of creating and populating the index.
#r "Newtonsoft.Json"
using System.Net;
using Newtonsoft.Json;
using Microsoft.Azure.Search;
using Microsoft.Azure.Search.Models;
public static async Task<HttpResponseMessage> Run(HttpRequestMessage req, TraceWriter log)
{
WebClient client = new WebClient();
client.Encoding = System.Text.Encoding.UTF8;
string value = client.DownloadString("https://hutchcodes.net/search.json");
var searchTopics = JsonConvert.DeserializeObject<List<Page>>(value);
var indexClient = RecreateIndex();
var batch = IndexBatch.Upload(searchTopics);
indexClient.Documents.Index(batch);
}
private static SearchIndexClient RecreateIndex()
{
var queryApiKey = "[Your API Key]";
var searchServiceName = "[You Search Service Name]";
var searchIndexName = "[Your Index Name]";
var searchServiceClient = new SearchServiceClient(searchServiceName, new SearchCredentials(queryApiKey));
if (searchServiceClient.Indexes.Exists(searchIndexName))
{
searchServiceClient.Indexes.Delete(searchIndexName);
}
var definition = new Index()
{
Name = searchIndexName,
Fields = new[]
{
new Field("Id", DataType.String) { IsFilterable = true, IsKey = true },
new Field("Url", DataType.String) { IsRetrievable = true },
new Field("Type", DataType.String) { IsFilterable = true, IsRetrievable = true, IsFacetable = true },
new Field("Title", DataType.String) { IsSearchable = true, IsRetrievable = true, Analyzer = AnalyzerName.EnMicrosoft },
new Field("Categories", DataType.Collection(DataType.String)) { IsFilterable = true, IsRetrievable = true, IsFacetable = true },
new Field("Tags", DataType.Collection(DataType.String)) { IsFilterable = true, IsRetrievable = true, IsFacetable = true },
new Field("Content", DataType.String) { IsSearchable = true, Analyzer = AnalyzerName.EnMicrosoft },
new Field("Excerpt", DataType.String) { IsSearchable = true, IsRetrievable = true, Analyzer = AnalyzerName.EnMicrosoft },
new Field("PublishDate", DataType.String) { IsRetrievable = true }
}
};
searchServiceClient.Indexes.Create(definition);
var indexClient = searchServiceClient.Indexes.GetClient(searchIndexName);
return indexClient;
}
public class Page
{
public string Id { get { return Url.GetHashCode().ToString(); } }
public string Url { get; set; }
public string Type { get; set; }
public string Title { get; set; }
public DateTime? PublishDate { get; set; }
public string Content { get; set; }
public string Excerpt { get; set; }
public List<string> Categories { get; set; }
public List<string> Tags { get; set; }
}
Starting from the bottom, the Page class represents the JSON objects that are output in the search.json, and the properties need to match 1 for 1 with the fields in the Index.
Each time we update the index we delete and recreate the index. We do this because if we delete a post or a page it gets removed from the search.json, but there is no way to trigger it’s removal from the Index. This could produce a result to be shown to the user that results in a 404.
Lastly (or firstly), the Run method gets the search.json from the blog, deserializes it into a List<Page> and uploads that list to the Search Index. Last I looked there was a limit of 1000 items per batch. I handle that potential problem in my GitHub example, but left that out here for simplicity.
Search Function
Finally, we’re able to start searching. First thing to do is create a Search function. To do this create an Http Trigger function and change the Authorization level from Function to Anonymous. By default the Url for this function will be /api/search. We’ll need to include a project.json with the same reference to the Azure Search SDK as we had in the BlogIndexer function. We’re also going to have a bit of duplicate code for the Page class and IndexClient (there’s ways to share code, but again trying to keep it simple for this post).
#r "Newtonsoft.Json"
using Microsoft.Azure.Search;
using Microsoft.Azure.Search.Models;
using Newtonsoft.Json;
public static async Task<HttpResponseMessage> Run(HttpRequestMessage req, TraceWriter log)
{
// parse query parameter
string search = req.GetQueryNameValuePairs()
.FirstOrDefault(q => string.Compare(q.Key, "search", true) == 0)
.Value;
string cat = req.GetQueryNameValuePairs()
.FirstOrDefault(q => string.Compare(q.Key, "cat", true) == 0)
.Value;
var results = Search(search, cat);
return req.CreateResponse(HttpStatusCode.OK, results);
}
private static List<Page> Search(string search, string facet)
{
var queryApiKey = "[Your API Key]";
var searchServiceName = "[You Search Service Name]";
var searchIndexName = "[Your Index Name]";
var indexClient = new SearchIndexClient(searchServiceName, searchIndexName, new SearchCredentials(queryApiKey));
string facetFilter = "";
if (!string.IsNullOrEmpty(facet))
{
facetFilter = $"Categories/any(c: c eq '{facet}')";
}
var searchParams = new SearchParameters();
searchParams.IncludeTotalResultCount = true;
searchParams.QueryType = QueryType.Full;
searchParams.SearchMode = SearchMode.Any;
searchParams.Top = 10000;
searchParams.Select = new[] { "Url", "Type", "Title", "Excerpt", "Categories", "PublishDate" };
searchParams.Filter = facetFilter;
searchParams.Facets = new[] { "Categories" };
var searchResults = indexClient.Documents.Search<Page>(search, searchParams);
var pages = new List<Page>();
foreach (var r in searchResults.Results)
{
pages.Add(r.Document);
}
return pages;
}
public class Page
{
public string Id { get { return Url.GetHashCode().ToString(); } }
public string Url { get; set; }
public string Type { get; set; }
public string Title { get; set; }
public DateTime? PublishDate { get; set; }
public string Content { get; set; }
public string Excerpt { get; set; }
public List<string> Categories { get; set; }
public List<string> Tags { get; set; }
}
Once that’s in place you can go to [Your function app URL]/api/search?search=foo&facet=bar and you should see some results. Don’t be shocked if it comes back as Xml, when you make the request from javascript on your page you can specify that you want JSON.
Before going on to setup search on the client side you need to update the CORS settings for the Function App. To do that through the portal you can click on Function app settings click on Configure CORS then add your blog’s domain and localhost:4000 to the list.
Searching
To do the search from my Jekyll based site I created a search.md page that looked for a search and cat query string and made a call to the API. Anywhere I started a search (clicking on a category or hitting enter in the search box), I forwarded the user to this search page with the appropriate query string.
On that page, I make a request to the Search function which returns a JSON of the results. I then loop through the results to build up some HTML as a string and stick it in the innerHtml of the appropriate element on the page.
My search page looks like this
---
title: Searching...
layout: search
includeInSearch: false
permalink: /search/
published: true
---
<script>
var query = getParameterByName('search');
var cat = getParameterByName('cat');
var tag = getParameterByName('tag');
document.getElementById("searchText").value = query;
getSearchResult(query, cat, tag);
</script>
The JavaScript to actually perform the search and display the results.
var searchUrl = '[URL of the Azure Function that performs the search]';
function searchKeyPress(e){
if (e.keyCode != 13) return;
var searchText = document.getElementById('searchText').value;
var cat = getParameterByName('cat');
var tag = getParameterByName('tag');
var catFilter = '';
var tagFilter = '';
if (!searchText) searchText='';
searchText = encodeURIComponent(searchText);
if (cat) catFilter = '&cat=' + cat;
if (tag) tagFilter = '&tag=' + tag;
window.location.href = '/search?search=' + searchText + catFilter + tagFilter
}
function getSearchResults(searchText, cat, tag) {
appInsights.trackEvent("Search", { search: searchText, category: cat, tag: tag });
if (!searchText) searchText = '';
if (!cat) cat = '';
if (!tag) tag = '';
searchUrl += '?search=' + searchText + '&cat=' + cat + '&tag=' + tag;
var xhr = new XMLHttpRequest();
xhr.onreadystatechange = searchCallback;
xhr.open('GET', searchUrl, true);
xhr.send('');
document.xhr = xhr;
function searchCallback(){
if(xhr.readyState === 4) {
if(xhr.status !== 200) {
alert('Search failed! ' + xhr.status + xhr.responseText);
return;
}
var searchResults = JSON.parse(xhr.responseText);
window.searchResults = searchResults;
displaySearchResults(searchResults);
}
}
}
function displaySearchResults(searchResults){
var response = '';
var main = document.getElementById('main');
var section = document.getElementById('main').getElementsByTagName("section")[0];
for (var x=0; x < searchResults.Results.length; x++)
{
var r = searchResults.Results[x];
if (r.Document.Type == "post") {
var categories = "";
for (var y=0; y < r.Document.Categories.length; y++)
{
var c = r.Document.Categories[y];
categories += "<a href='/search/?search&cat=" + c + "'>" + c + "</a> ";
}
if (!categories)
{
categories = " in " + categories;
}
response += "<article class='post'> <header class='jumbotron'> <h2 class='postTitle'><a href='" + r.Document.Url + "'>" + r.Document.Title + "</a></h2> <abbr class='postDate' title='" + r.Document.PublishDate + "'>" + new Date(r.Document.PublishDate).toLocaleDateString("en-us", {year: "numeric", month: "long", day: "numeric"}) + "</abbr> " + categories + "</header> <div class='articleBody'>" + r.Document.Excerpt + "</div><div><a href='" + r.Document.Url + "'>Continue Reading</a></div></article>";
}
else
{
response += "<article class='post'> <header class='jumbotron'> <h2 class='postTitle'><a href='" + r.Document.Url + "'>" + r.Document.Title + "</a></h2></header> <div class='articleBody'>" + r.Document.Excerpt + "</div><div><a href='" + r.Document.Url + "'>Continue Reading</a></div></article>";
}
}
if (response){
section.innerHTML = response;
}
else{
document.getElementById("searchMessage").innerHTML = "No results found."
}
}
function getParameterByName(name, url) {
if (!url) {
url = window.location.href;
}
name = name.replace(/[\[\]]/g, "\\$&");
var regex = new RegExp("[?&]" + name + "(=([^&#]*)|&|#|$)");
var results = regex.exec(url);
if (!results) return null;
if (!results[2]) return '';
return decodeURIComponent(results[2].replace(/\+/g, " "));
}
*It’s not quite free
I’m using the free tier of Azure Search, and Azure Functions allows 1 million function calls and 400k Gbs of execution for free. In theory, there is no charge unless it gets a lot of use.
But it’s still not quite free. I have been charged $.03. Looking at this, it turns out that some of that is from a couple of days when my function wasn’t compiling but was getting called by one of my Application Insights Web Tests. That caused the function to be reloaded from the Function App’s Storage Account racking up $.02.
The other $.01 has come from the App Service behind my Function App, but I can’t see where. There is no single day where there is a $.01 charge, so I’m guessing it’s the cummulation of fractions of a cent per day.
I’d like this to be 100% free, but I’m not going to spend my time finding out why I’m being charge $.03/month.
Addition resources
- Source code for the Azure Functions that are handling search on this site, included is a Jekyll folder with most of what you’ll need to get it running on your site. The only things missing are the search box and the category displays that would like to
/search?cat=[category name]
If you get stuck, I’d love to help. Feel free to contact me through any method available on my about page.
Have a comment or suggestion? This blog takes pull requests.Or you can just open an issue.